

Mapping Your Attack Surface with IONIX’s ASM Platform

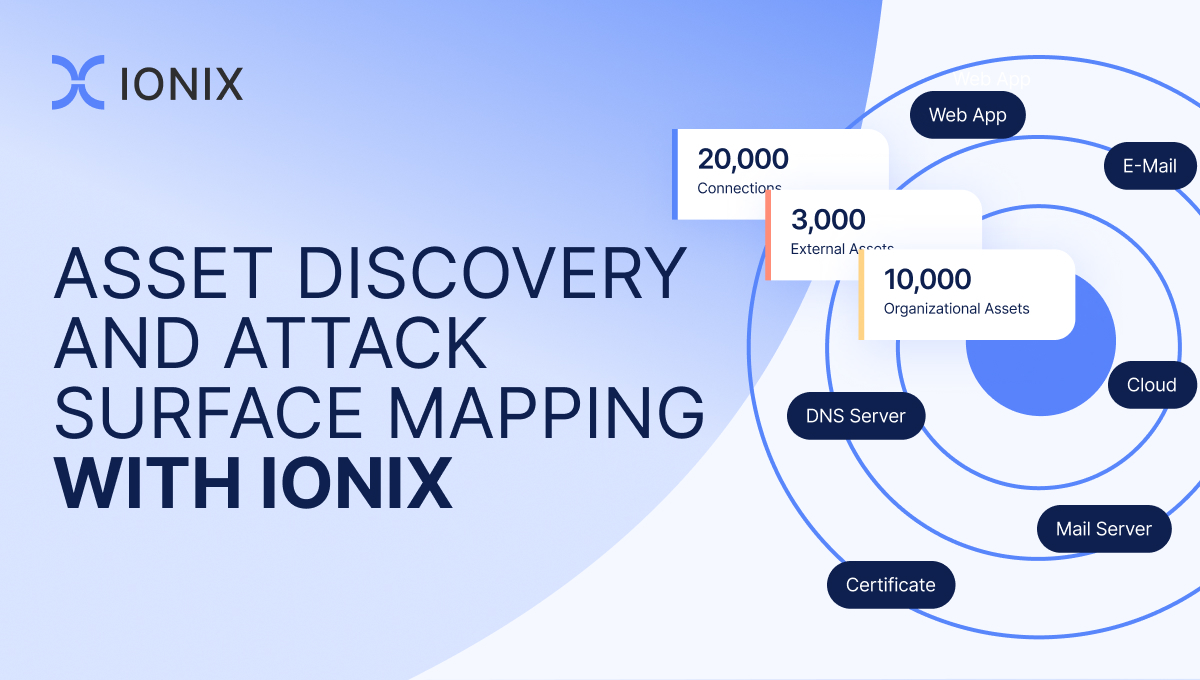
External Attack Surface Management, or EASM, empowers organizations to proactively manage and secure their digital presence in an ever-evolving threat landscape. There are two critical EASM processes that this blog post will cover – Asset Discovery and Attack Surface Mapping.
What is the Asset Discovery Process?
The IONIX asset discovery process begins with the collection of seed data, including keywords and domains. From there, an automated process kicks in, utilizing various external sources to identify relevant organizations. Data fusion techniques are then employed to validate and refine the results, minimizing false positives.
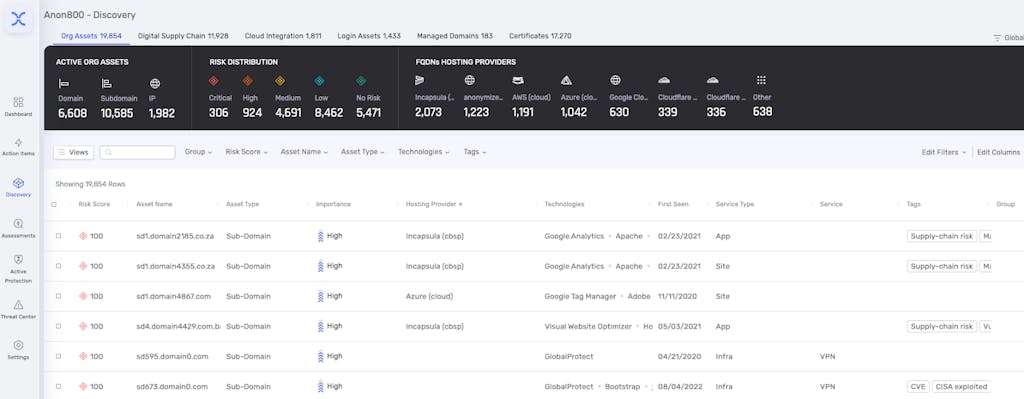
The asset discovery process encompasses various facets, including the identification of top domains, sub-domains, IPs, managed domains, unlinked IPs and more. Techniques such as reverse searches and passive DNS are utilized to uncover these assets. Machine learning algorithms and proprietary classification methods aid in the categorization and attribution of discovered assets.
Going beyond Asset Inventory: Attack Surface Mapping
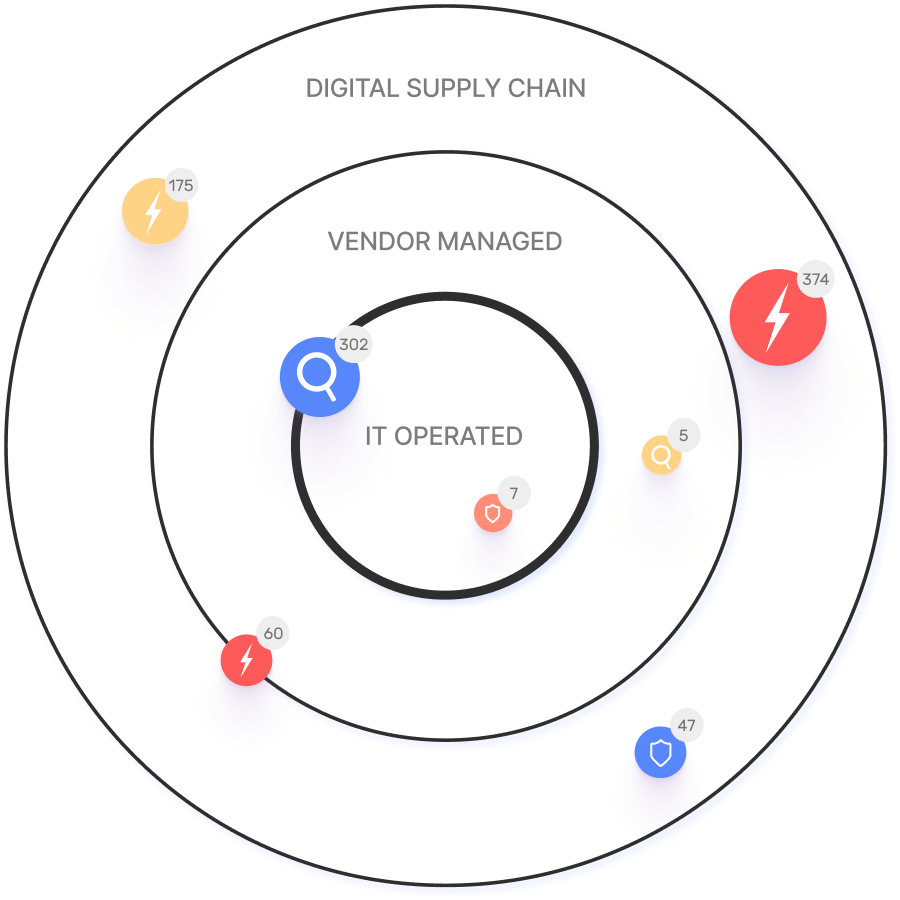
Importantly, the asset discovery process is not a one-time event but a continuous cycle of learning and refinement. At IONIX, as opposed to other EASM tools, the discovery inventory gives way to creation of a more complete attack surface map of connected assets. We refer to this as ‘Connective Intelligence’. By iteratively analyzing the inventory and incorporating new data insights, organizations can enhance the accuracy and depth of their attack surface map in order to prioritize assets for remediation.
Post-discovery, the management of subsidiaries, evidence collection, and the addition/removal of assets is done, to map out connected assets in ways that are valuable for organizations. With an attack surface map, customers can see connected assets and their dependencies deep into vendor-managed and even their connected assets, known as the digital supply chain.
How is Asset Discovery Performed?
Scheduled scans, both automatic and manual, ensure ongoing monitoring and maintenance of the organization’s attack surface.
The Asset Discovery scan, using the seed data (which includes names and domains) collects the following information:
- Domains (top domains and subdomains), IPs, managed domains and unlinked IPs.
- Domain candidate search – Utilizing the initial set of seed data to scout for candidates, using the following tools and techniques:
- Reverse domain lookups
- IP lookups including logos and favicons
- Certificates lookups
- DNS records lookups and reverse lookups
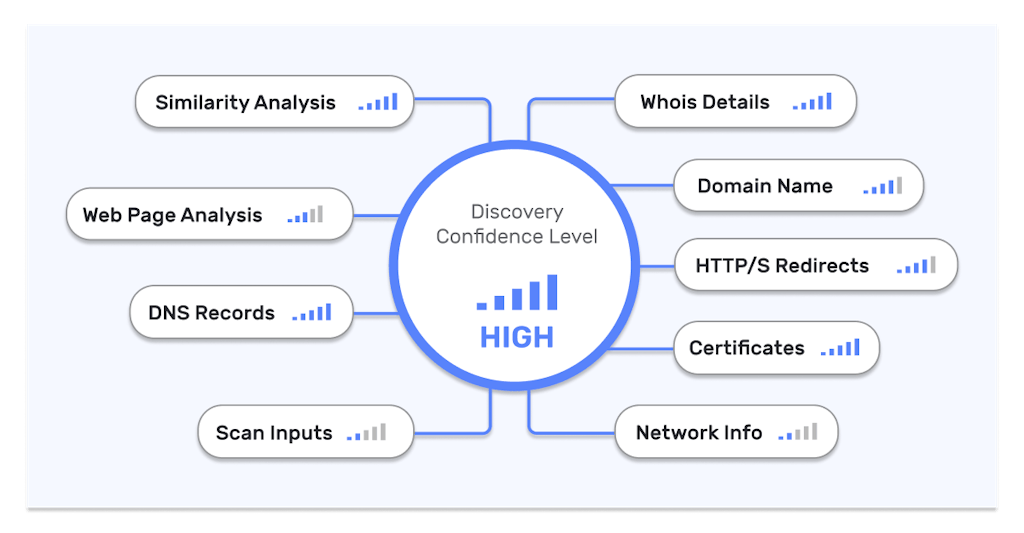
- Domain classification – Classifying all candidates using various classification methods such as:
- Proprietary algorithms – analyzing each of the candidate domains to find similarities to the seed data.
- Machine Learning – running several ML algorithms on top of our algorithms, and if the performance of the ML is as accurate as our algorithms, it’ll be used for further analysis of undecided candidates.
- Connected components – this method employs the similarity of distinct features across domains to categorize candidates into cohesive groups, such as WHOIS data, DNS, and HTML. For instance, domains exhibiting similar characteristics, such as redirecting to the same domain and sharing identical Second-Level Domains (SLDs), are linked together.
Understanding The Attack Surface Map
During the crawling process, the crawler identifies and captures:
- Additional assets: Beyond the initially identified assets, the crawler discovers supplementary web assets, expanding the organization’s inventory and ensuring a comprehensive understanding of its online presence.
- Third-party dependencies: By analyzing the connections each of the organization’s assets has, the crawler uncovers their digital supply chain, or the third-party dependencies utilized by the organization. This can include any external code used by the organization, files, APIs etc.

Also, the crawler has the following capabilities and benefits which add context to the attack surface map:
- Technologies and CPEs (Common Platform Enumeration): Through in-depth analysis, the crawler identifies the technologies, versions, frameworks, and software solutions utilized by various web assets. This provides crucial insights into the organization’s technological landscape and potential vulnerabilities.
- Login pages: The crawler identifies login pages within the assets, enabling further investigation into authentication mechanisms and potential security risks.
Continuous Improvement: Following the crawler steps listed above, our discovery process enters a phase of continuous improvement. With each iteration, IONIX accumulates additional data about the organization’s digital assets, enabling us to refine and enhance our discovery techniques. By leveraging insights gained from previous scans, we identify more key names and domains, ensuring a more comprehensive understanding of the organization’s attack surface.
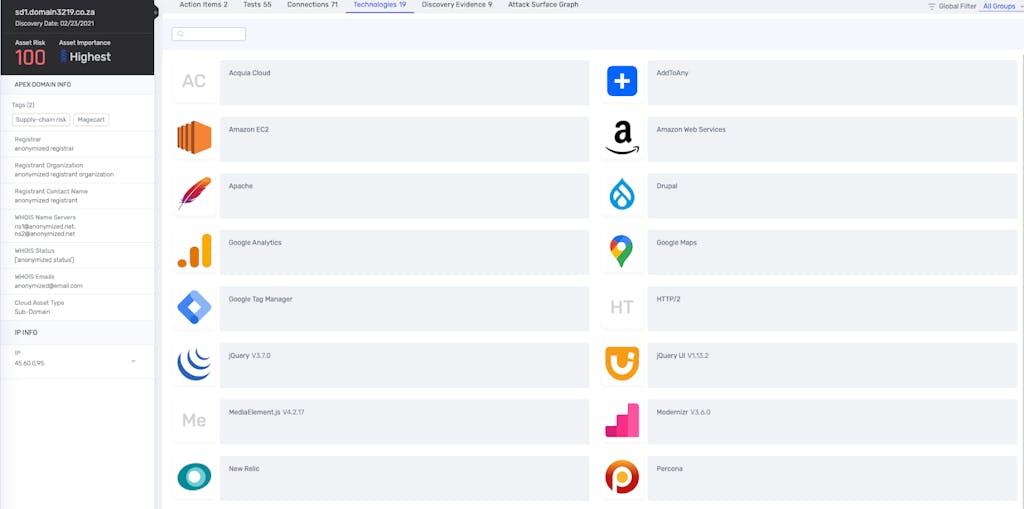
Through this iterative approach, we start each subsequent scan from an improved starting point, incorporating new data and insights to achieve greater accuracy and depth in asset discovery. This ongoing cycle of learning and refinement enables us to uncover previously undiscovered assets, to map those assets and then to assess asset importance and priority.
By leveraging a combination of automated tools, data fusion techniques, and validation processes, IONIX provides a thorough understanding of each organization’s digital assets, starting from seed assets, and continuing to domains, IPs, managed domains, unlinked IPs and more. The ever-growing attack surface every organization must manage starts with continuous discovery and prioritization.


