

How to Implement Multi-Factor Asset Attribution in Attack Surface Discovery

As organizations navigate through the complexities of the digital era, the challenge of accurately identifying and managing their asset inventory has become a critical aspect of their security posture. This task, known as attack surface discovery and asset attribution, involves a delicate balance: identifying all assets that belong to the organization while ensuring that no extraneous ones are included. Achieving this balance is essential to minimize both false negatives (blind spots or unknowns) and false positives (assets mistakenly attributed to the organization), each carrying significant risks.
The goal of Attack Surface Discovery: Identify everything that belongs to the organization and none that does not.
In this article
What are false negatives and what are their risks?
False negatives represent a significant security risk in attack surface management. These are the assets that belong to the organization but remain unidentified and, consequently, unprotected. Such blind spots in an organization’s digital landscape often become gateways for cyber threats, as attackers can easily exploit these overlooked assets. According to a recent ESG survey, 76% of organizations’ experienced an attack that originated in an unknown or unmanaged internet facing asset.
What are false positives and what are their risks?
On the other hand, false positives may not be immediately threatening, but often lead security and IT teams on frustrating wild goose chases. When security tools mistakenly identify assets as part of an organization’s IT, valuable time and resources are wasted trying to track the owner of an asset that does not belong to the organization. This misdirection diverts critical attention and resources away from genuine threats and vulnerabilities. Even worse, this exercise in futility erodes the trust security teams have with their IT stakeholders.
The Challenge of Attack Surface Discovery
The primary challenge of attack surface discovery stems from the dynamic and expansive nature of modern IT environments. Today’s organizations operate across a multitude of platforms, including on-premises infrastructure, cloud services, vendor-managed platforms, and SaaS environments. This diversity, coupled with the rapid pace of technological advancements and changes, makes it increasingly difficult to maintain a comprehensive and up-to-date inventory of all assets. The attack surface is not static; it evolves continuously as new technologies are adopted, existing systems are updated, and organizational structures change, internal and external.
Limitations of Simplistic Discovery Approaches
Traditional attack surface management solutions often employ simplistic, linear approaches to discovery. This method typically involves tracing assets through direct, deterministic paths from ‘seed assets’. For example, the discovery process might follow a sequence such as domain to subdomain to IP address.
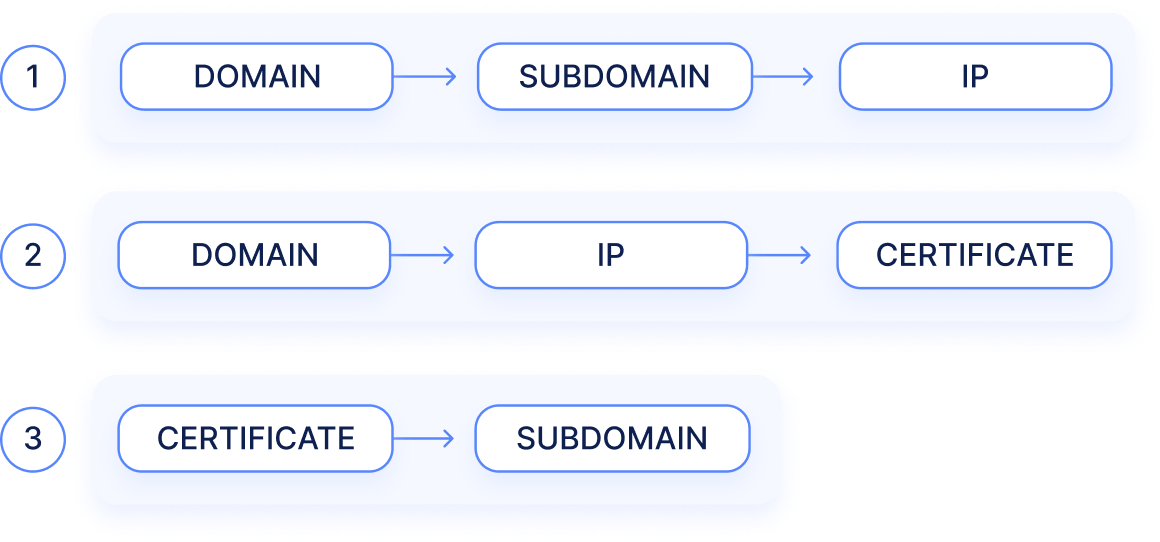
A direct approach tends to yield low false positives but it is plagued by a high rate of false negatives because it overlooks less obvious assets. For example, assets without clear ‘Whois’ records or assets with subtle indicators like metadata or visual characteristics.
In fact, linear attribution graphs are strong indicators that a simplistic discovery approach, which is prone to false negatives, is operating behind the scenes. As we explain in the next sections, minimizing false positives requires a multi-factor attack surface discovery process and multi-factor attribution model.
Avoiding False Negatives with Multi-Factor Discovery
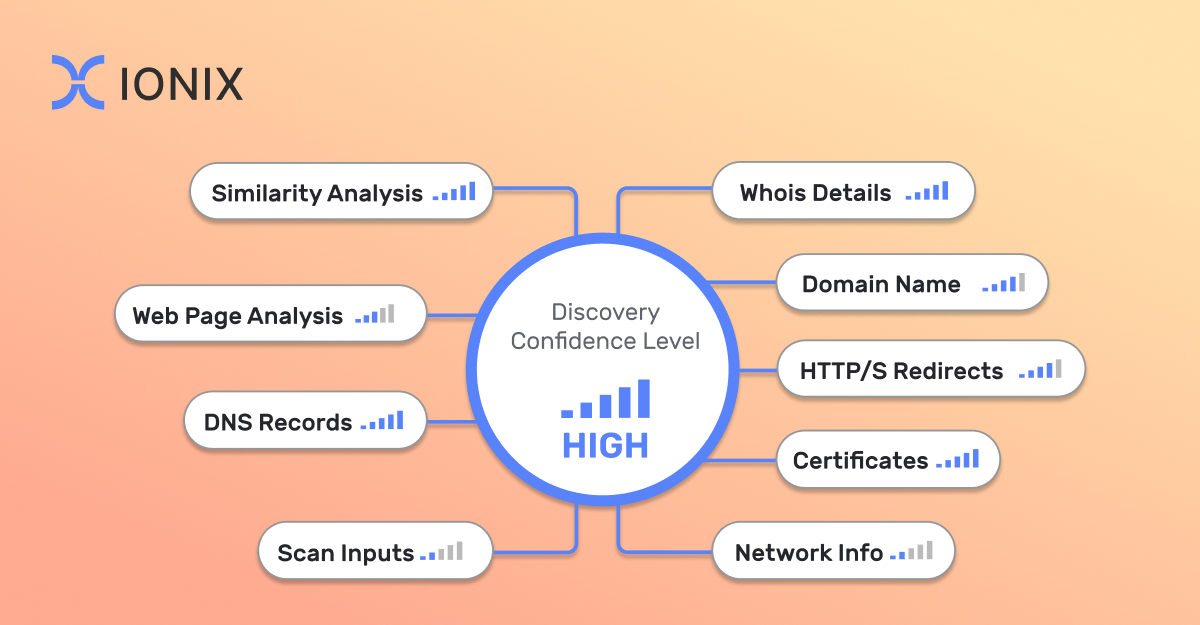
To effectively discover their attack surface, organizations must embrace a multi-factor discovery process. This approach goes beyond linear pathways, incorporating various methods and sources of information to build a comprehensive view of the organization’s digital footprint.
Key discovery methods are:
- Whois Records: Extracting details from the various fields of an asset’s Whois record to identify ownership and other relevant information.
- DNS Records: Investigating records like nameserver, SOA, MX, etc., for hidden details that might indicate asset ownership or association.
- Domain names: Examining Domain URLs to uncover related terms, names, or identifiers embedded within them that are significant.
- Certificates: Utilizing details from asset certificates, such as organization names and common names, to establish connections and ownership.
- Web: Rendering a domain’s HTML content, metadata, and visual elements to uncover subtle indications of asset ownership.
- Network Information: Analyzing IP records and CIDRs associated with the domain to map the network footprint of the organization.
- HTTP/S Redirects: Investigating URLs that redirect to the asset for indicative names that might reveal ownership or association.
- Similarity Analysis: Comparing elements, whether visual or otherwise, for similarities that might indicate common ownership or association.
- Customer Input: Incorporating data provided by the organization, such as domain names or brand names, to enhance the discovery process.
The multi-factor approach to asset discovery is effective in reducing false negatives. By combining multiple weaker indicators, it will identify less obvious organizational assets and reduce blind spots. However, the added complexity makes asset attribution more challenging as well. In the next section, we will review how to minimize false positives in asset attribution.
How to avoid false positives
Multi-factor attack surface discovery requires a new approach to asset attribution; one that continually learns the organization’s digital footprint and automatically adapts to changes. At the same time, the attribution process must scale efficiently to support enterprises with hundreds of thousands of assets. This means that achieving precision cannot come at the cost of the labor or resource intensive process. Machine learning algorithms are best suited for the task of attributing assets with low false positives, while continually improving and adapting to changes.
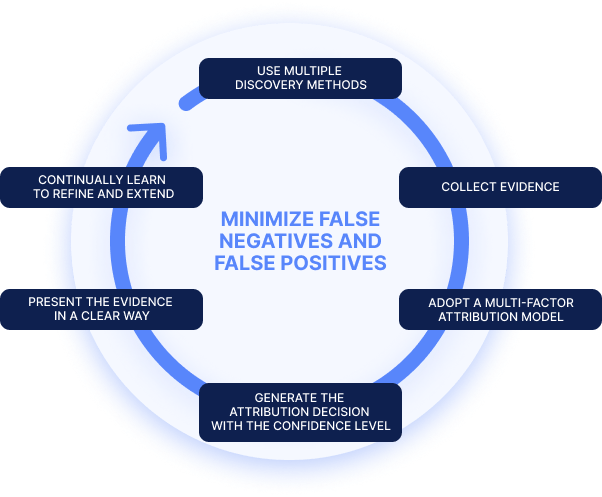
- Use multiple discovery methods to improve coverage.
- Collect evidence from every discovery method.
- Adopt a multi-factor attribution model to integrate and analyze all the findings. Machine learning models are very useful for this purpose.
- Generate both a decision whether the asset belongs to the organization but also the confidence level that properly reflects weaker findings.Since attribution is not a ‘black and white’ decision, a confidence score is needed to communicate the outcome.
- Present the outcome, confidence level, and all the evidence in a clear way. Due to the size and complexity of modern enterprise IT, this view is crucial. Security and IT teams are often unaware of large areas in their organization’s attack surface and require as much information as possible to bring these under control.
- Evidence collected and attribution decisions should be used as inputs for the next discovery iteration. This helps to refine and extend the discovery and attribution process.
Reducing false negatives and false positives with IONIX ASM
IONIX Attack Surface Management solution employs a comprehensive multi-factor discovery and attribution process, using machine learning to accurately identify organizational assets. This solution presents the discovery evidence in a clear unified view that enables security teams to effectively manage and control their organization’s digital footprint.
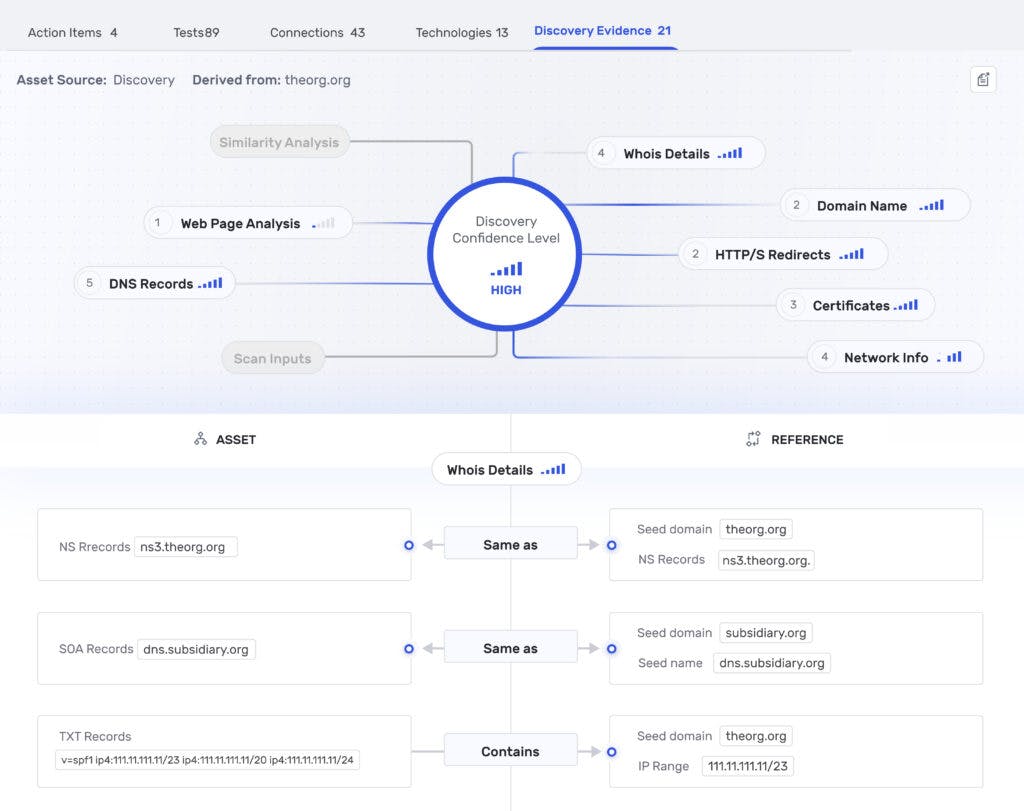
IONIX’s Multi-Factor Discovery
IONIX employs a multi-factor discovery process to effectively map an organization’s attack surface and discover up to 50% more organizational assets in comparison to simplistic discovery solutions. IONIX attack surface discovery integrates various methods and information sources to construct a comprehensive view of the organization’s digital footprint. Key elements include examining Whois and DNS records, domain names, asset certificates, web page content, network information, HTTP/S redirects, similarity analysis, and customer input. This multifaceted strategy is crucial for identifying less obvious organizational assets, reducing blind spots, and false positives.
IONIX’s Machine Learning Asset Attribution
To minimize false positives, IONIX adopts a multi-factor approach to asset attribution that continually learns and adapts to the organization’s digital footprint. This process is designed to be efficient and scalable, even for enterprises with extensive asset inventories. Machine learning algorithms play a crucial role in attributing assets with low false positives. The system not only decides whether an asset belongs to the organization but also assigns a confidence level to reflect the strength of the findings. The outcome, along with the confidence level and all evidence, is presented clearly to aid security and IT teams in managing their attack surface.
IONIX Discovery Evidence View
The IONIX Discovery Evidence View provides security professionals with transparent visibility into the evidence collection and attribution process. This unified view reflects the complex nature of asset discovery and attribution. It demonstrates all the evidence collected on an asset and how this information contributes to the conclusion. The evidence is presented in relation to a seed asset or keyword and compared across the discovery methods, offering a comprehensive and understandable insight into the attribution process. Read more in the IONIX Discovery Evidence datasheet.
To see IONIX Discovery Evidence in action on your attack surface, request a scan.


